LLM + 시스템 프롬프트 + RAG + 파인튜닝
"문서를 더 넣을까, 모델을 더 줄일까?" 2026년 LLM 팀들이 매일 하는 고민을 한 번에 정리했습니다.
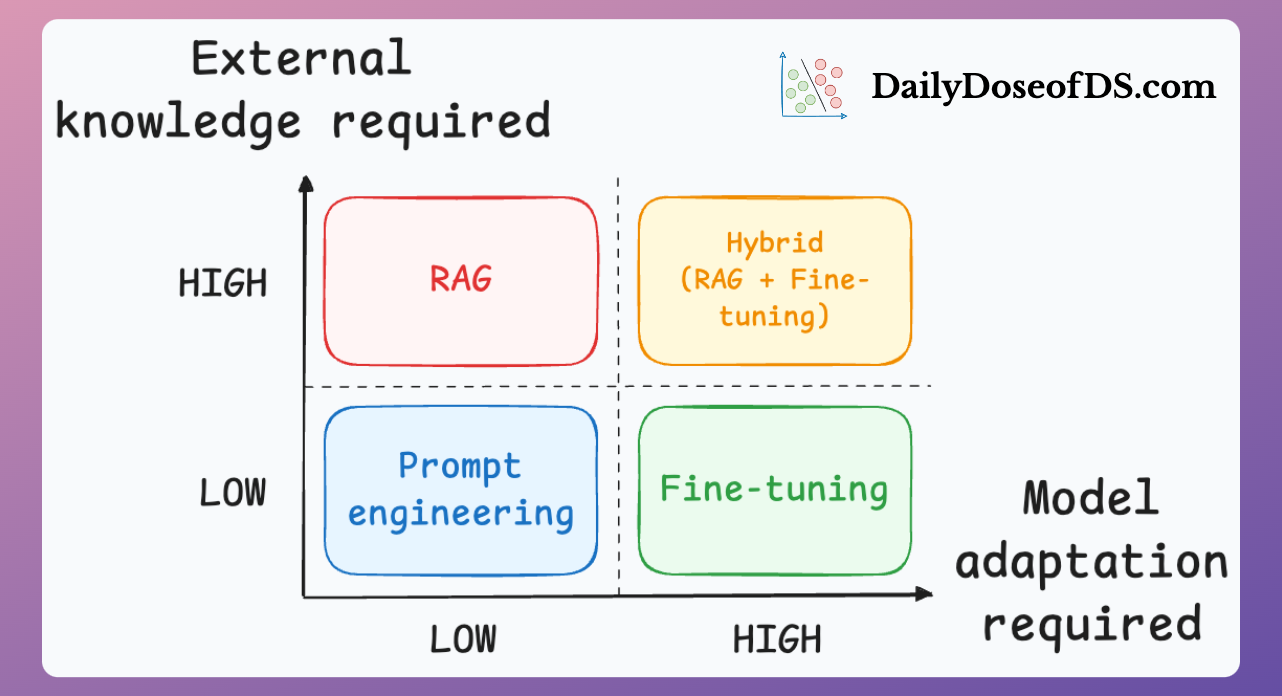
1. 2026년 스택 맥락
- 멀티모달 모델 보급: GPT-4.1, Gemini 2.0, Llama 3.2 Vision 등이 텍스트·이미지를 함께 처리하면서 입력 컨텍스트가 다양해졌습니다.
- RAG 도구 성숙: LanceDB, Weaviate 2.x, Pinecone PARSE와 같은 "hybrid search + structured query" 기능이 기본이 됐습니다.
- 파인튜닝 플랫폼: OpenAI의 Custom Model, Amazon Bedrock, Together AI FineTune 등 상용 서비스가 Llama·Mixtral 계열까지 지원하면서 재훈련 장벽이 낮아졌습니다.
- 시스템 프롬프트 엔지니어링: Claude Prompt Generator, OpenAI Prompt Management, Guidance DSL 같은 도구로 시스템 메시지를 버전 관리하며, 정책·콘텍스트를 코드처럼 관리하는 팀이 늘었습니다.
2. 시스템 프롬프트로 토대를 다지기
- 역할 정의:
You are a compliance analyst...형태만으로는 부족합니다. 목적·권한·금지 행위를 JSON으로 정리하고, 프롬프트 템플릿에 주석을 달아 Git으로 추적하세요. - 리워드 구조: RAG나 파인튜닝 전에도 시스템 메시지에서 "답변할 수 없는 경우 반드시 [추가 정보 요청]으로 응답" 같은 가드레일을 정의하면 후속 비용이 줄어듭니다.
- 버전 관리:
prompts/system/v3.md처럼 버전명을 붙이고, 실험마다 Langfuse/Arize에 어떤 시스템 프롬프트가 쓰였는지 태깅합니다. - A/B 테스트: PromptLayer, Guidance, OpenAI Prompt Management를 이용해 시스템 프롬프트 후보를 나란히 배포하고, 실제 사용자 피드백을 수집합니다.
3. RAG와 파인튜닝, 언제 무엇을 쓸까?
| 요구사항 | 순수 RAG | 파인튜닝 | 하이브리드 |
|---|---|---|---|
| 최신성 | ✅ 문서 교체만으로 반영 | ❌ 재훈련 필요 | ✅ RAG 파트로 커버 |
| 도메인 용어 정착 | △ 지식 그래프/메타데이터 필요 | ✅ 모델 자체에 주입 | ✅ 핵심 개념만 파인튜닝 |
| 응답 스타일 일관성 | △ 프롬프트 템플릿 의존 | ✅ 파인튜닝으로 톤 확보 | ✅ 파인튜닝 + RAG 지식 |
| 비용/속도 | ✅ 저장소만 관리 | ❌ 학습/추론 비용 증가 | △ 선택적 파인튜닝 |
| 보안/온프레미스 | ✅ 자체 벡터 DB로 운영 | ✅ 사내 GPU 클러스터 사용 | ✅ 구성 복잡하지만 유연 |
4. 하이브리드 파이프라인 예시
- 지식 계층
- 장기: Weaviate Hybrid Index (BM25 + Dense) + JSON 브라우저 필터
- 단기: Redis/Vald 캐시, 실시간 스트리밍 로그
- 모델 계층
- 베이스: Llama 3.2 70B Instruct (LoRA 어댑터 적용)
- 파인튜닝: 도메인 톤/금칙어 데이터 5k 샘플로 Delta 모델 생성
- 오케스트레이션
- LangGraph/Flowise로 Retrieval → Guardrail → Generation 그래프 설계
- "Critical QA" Path: Retrieval 이후 Re-Ranker (ColBERTv2) + Self-Consistency
- 평가
- Pydantic-evals, Ragas 0.1, OpenAI Evals 등을 조합해 정확도/최신성/톤을 각각 측정합니다.
5. 최신 기법 스냅샷 (2025 Q4 ~ 2026 Q1)
- Structured RAG: OpenAI Responses API + JSON Schema, MongoDB Atlas Vector Search의 $vectorSearch + $searchMeta 병행.
- Self-Reflective Fine-Tuning: OpenAI Custom Model의 "Memory Tuning" 기능으로 사용자 피드백을 Elastic Cache에 쌓고 주기적으로 재학습.
- Hybrid Retrieval Pipelines: Pinecone PARSE, LanceDB FUSION으로 키워드·벡터·Graphwalk를 한 번에 조회.
- LoRA + Function-Calling: Mixtral 8x22B에 LoRA를 적용하고 Function-Calling Adapters로 전략적 API 호출을 분리.
- LLMOps: Langfuse 2.1, Arize Phoenix, WeightWatcher로 추론 로그, 편향, 모델 드리프트를 동시에 추적.
6. 도입 체크리스트
- 데이터 청결: 중복 문서, PII, 라이선스 상태를 분류하고, RAG 인덱스와 파인튜닝 데이터셋 모두에 동일한 정책을 적용합니다.
- 프로파일링:
ragas,trulens_eval로 Retrieval Recall, Faithfulness, Answer Relevance를 측정하고, 파인튜닝 샘플 수를 결정합니다. - 토폴로지 설계: 엔드유저 플로우별로 그래프를 설계하되, 실패/재시도 경로를 명시합니다.
- 비용 감시: LLM API 비용, 벡터 DB 저장 비용, 파인튜닝 학습/추론 비용을 CloudWatch 혹은 FinOps 대시보드에 연결합니다.
- 릴리스 계획: 롤링 업데이트 대신 Canary/Shadow 모드를 두고, 실 사용자 피드백을 기반으로 파인튜닝·RAG 교체를 단계적으로 진행합니다.
7. 추천 설계 흐름
- RAG부터 시작: 문서화, FAQ, SOP를 벡터화하고 하이브리드 검색으로 최신성을 확보합니다.
- 파인튜닝으로 톤·컨텍스트 보강: 반복되는 톤 문제나 구조화된 답변이 필요할 때 LoRA 혹은 Adapter 방식으로 경량 학습합니다.
- 오케스트레이터로 통합: LangGraph, CrewAI 등으로 의사결정 루프를 분리해 재시도/검증 경로를 명확히 합니다.
- 관찰성과 실험: Langfuse/Arize를 붙이고, Prompt/Model 버전 매트릭스를 운영해 어디에서 성능 변동이 생겼는지 추적합니다.
RAG와 파인튜닝은 양자택일 관계가 아니라, 각자의 강점을 결합할 때 ROI가 극대화됩니다. 2026년에는 최신 검색 기술, 경량 파인튜닝, LLMOps 도구를 조합해, "무엇을 업데이트할지"를 빠르게 결정하는 팀이 경쟁우위를 갖게 됩니다.